Model fitting
2026-06-17
This vignette demonstrates how the unitcost, unitcost_fixed and unitcost_ohd models were fitted and sensitivity analyses performed. It also shows how models could be fit using different covariates, target variable, training data or priors.
The following functions were included in the package to make the process of model development transparent and reproducible, but if you want to use the final capturetb models to predict costs you should read vignette("01_unitcost-model-predictions") and vignette("02_combining-predictions-data") instead.
Creating a model instance
A model instance requires a list of covariates, a target variable to predict, training data, and priors for parameters.
covariates <- c("logVisits", "logVisitsPP", "logVisitsPP_TB", "urban", "public")
target <- "ID_unitcost_total"
# Specifying priors for the fixed effects
# One beta coefficient for each covariate
# Other parameters will take default values
priors <- capturetb::capturetb_priors(
beta.mean = rep(0, length(covariates)),
beta.precision = rep(0.01, length(covariates))
)
data <- capturetb::get_data(output_name = "op_diagnosticvisit")
# or provide your own data;
# see capturetb::outputs() for all output data
# installed with the packageWe now create an instance of the capturetb::JAGSModel class to fit a model with fixed covariate effects and country level random effects. If the data provided has more than one unique output type in the output column, the model will include facility and visit type effects. If the data has only one unique output type, no facility or visit type effects will be included.
model <- capturetb::JAGSModel$new(
dat = data,
covariates = covariates,
target = target,
priors = priors
)
#> Warning in initialize(...): Removed 3 rows with missing data.
#> Single output type detected. Not including output-level random effects in model.Priors can be visualised by calling plot(priors, par = "name_of_param"):
priors <- model$priors()
plots <- list()
for(i in 1:3) {
plots[[i]] <- plot(priors, par = paste0("beta[", i, "]"))
}
plots[[4]] <- plot(priors, par = "sigma_c")
plots[[5]] <- plot(priors, par = "sigma")
do.call(grid.arrange, c(plots, ncol = 3))
#> Warning: Removed 3341 rows containing missing values or values outside the scale range
#> (`geom_line()`).
#> Removed 3341 rows containing missing values or values outside the scale range
#> (`geom_line()`).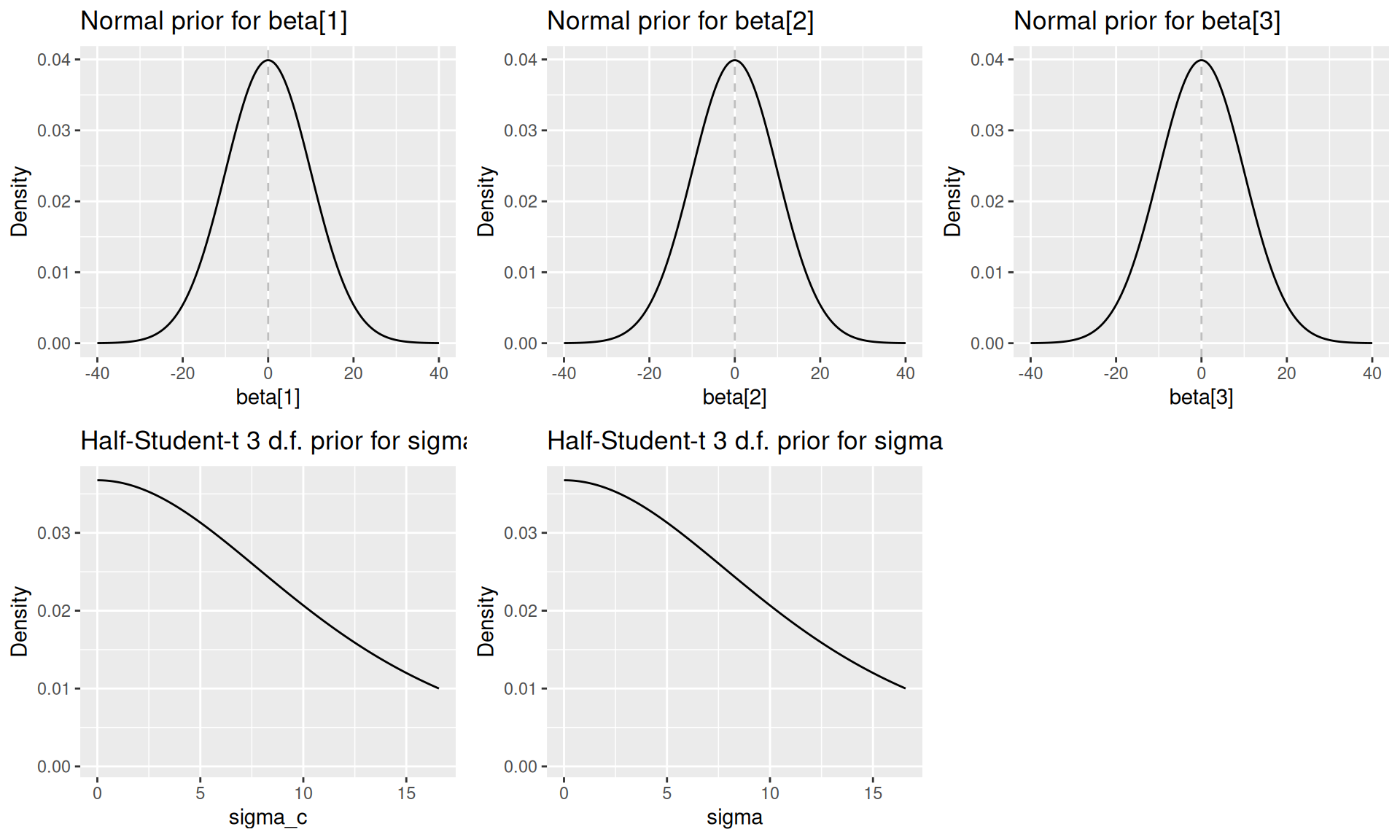
Fitting the model
Under the hood the JAGSModel class uses JAGS (Just Another Gibbs Sampler) to fit a multilevel linear regression model. To fit the model, JAGS and the runjags package must be installed on your machine.
For the purpose of the vignette, we’ll use fewer iterations than recommended for faster computation:
# Fit the model with reduced iterations for demonstration
# In practice, you might want to use the defaults (n.iter = 100000)
model$fit(
n.iter = 20000,
n.burnin = 1000,
n.thin = 5,
n.chains = 2
)
# Check summary statistics of the fitted samples
fitted_samples <- model$samples()
summary(fitted_samples)
#>
#> Iterations = 6001:25996
#> Thinning interval = 5
#> Number of chains = 2
#> Sample size per chain = 4000
#>
#> 1. Empirical mean and standard deviation for each variable,
#> plus standard error of the mean:
#>
#> Mean SD Naive SE Time-series SE
#> alpha 3.632990 0.57697 0.0064507 0.0410323
#> beta[1] -0.077730 0.05069 0.0005667 0.0033250
#> beta[2] 0.041133 0.05426 0.0006067 0.0007974
#> beta[3] -0.353817 0.09341 0.0010444 0.0019229
#> beta[4] 0.390974 0.13819 0.0015450 0.0022539
#> beta[5] -0.312759 0.12860 0.0014378 0.0017954
#> sigma 0.565541 0.04095 0.0004578 0.0004839
#> sigma_c 0.553044 0.35404 0.0039582 0.0113500
#> country_effect[1] -0.061765 0.30360 0.0033943 0.0128217
#> country_effect[2] -0.001481 0.31463 0.0035177 0.0134369
#> country_effect[3] -0.494762 0.31428 0.0035137 0.0126031
#> country_effect[4] 0.441338 0.30719 0.0034345 0.0133765
#> country_effect[5] 0.053625 0.32054 0.0035837 0.0142439
#>
#> 2. Quantiles for each variable:
#>
#> 2.5% 25% 50% 75% 97.5%
#> alpha 2.5599 3.247440 3.61766 3.99572 4.75051
#> beta[1] -0.1740 -0.112886 -0.07885 -0.04224 0.01830
#> beta[2] -0.0641 0.005107 0.04106 0.07673 0.14847
#> beta[3] -0.5419 -0.415911 -0.35220 -0.29131 -0.17237
#> beta[4] 0.1201 0.300016 0.39160 0.48393 0.65844
#> beta[5] -0.5697 -0.398288 -0.31254 -0.22698 -0.05856
#> sigma 0.4930 0.537184 0.56266 0.59083 0.65488
#> sigma_c 0.1959 0.338309 0.45647 0.65280 1.52093
#> country_effect[1] -0.6892 -0.207754 -0.04684 0.10998 0.49102
#> country_effect[2] -0.6414 -0.157581 0.01432 0.17668 0.56825
#> country_effect[3] -1.1575 -0.647886 -0.47052 -0.30560 0.03016
#> country_effect[4] -0.1579 0.278954 0.44596 0.61614 1.02688
#> country_effect[5] -0.5833 -0.117776 0.05976 0.23562 0.66353Diagnostics
Several functions are available on the model class to check whether the model has converged:
Rhat:
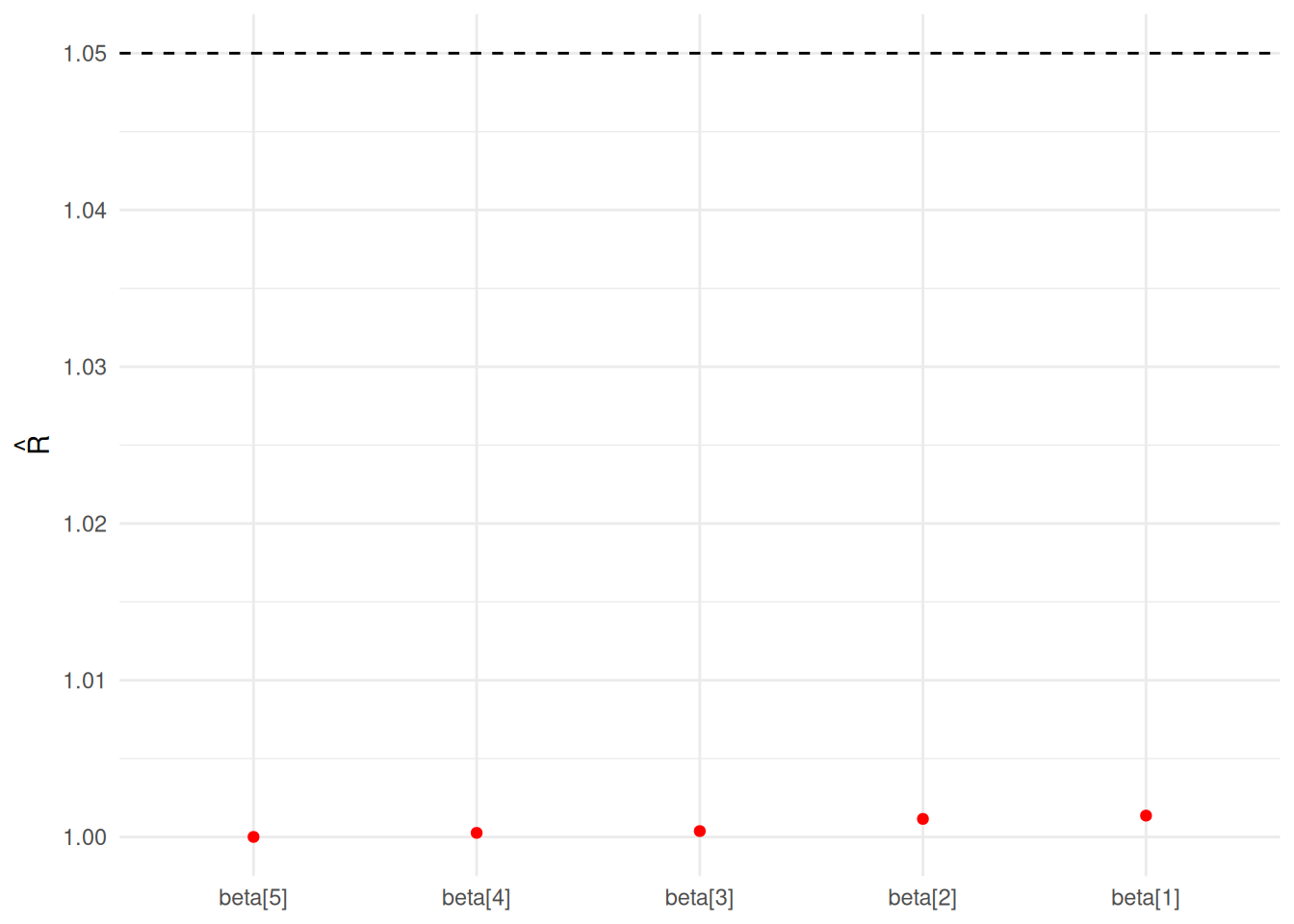
Trace:
model$mcmc_trace(regex_pars = "beta")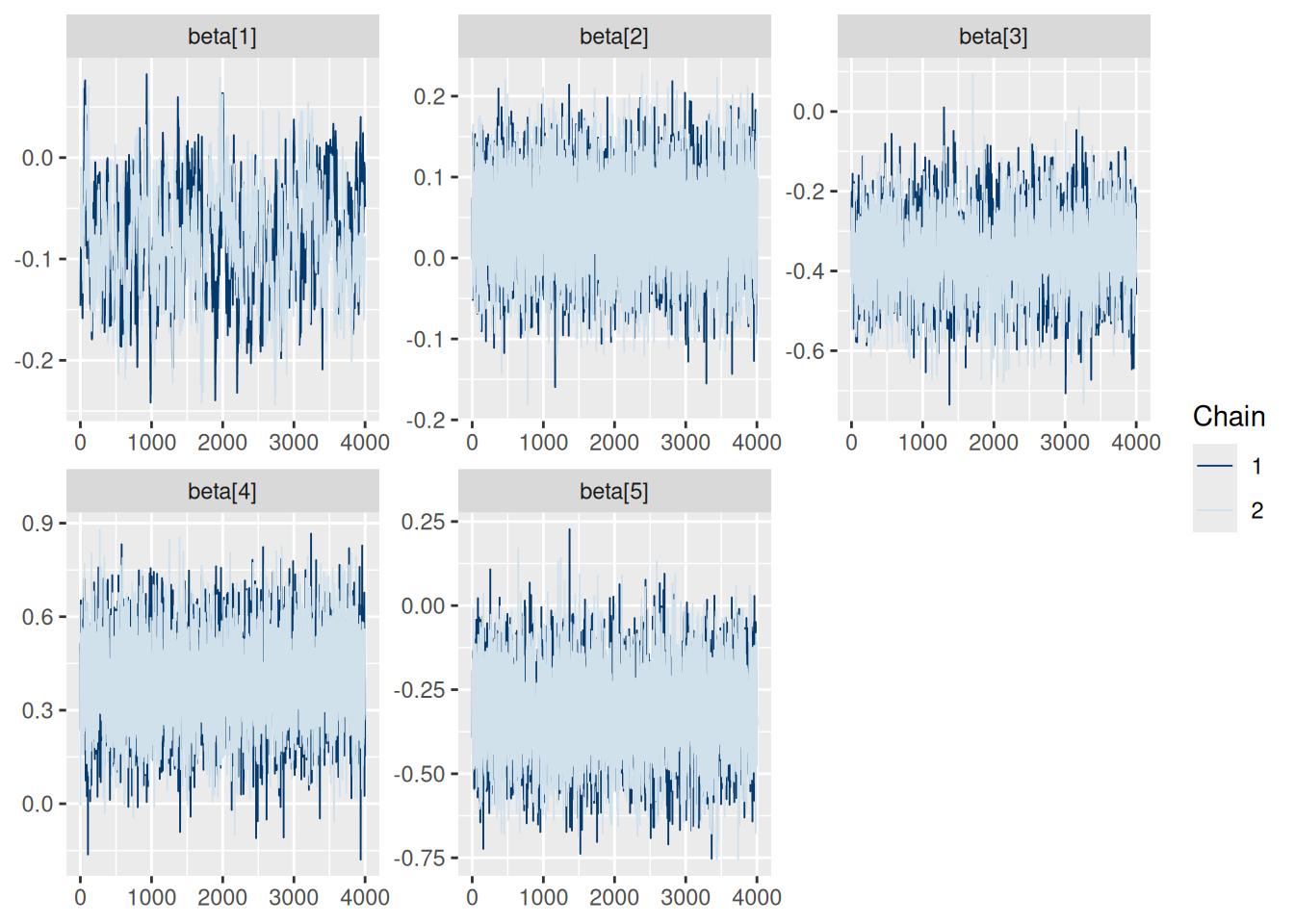
Auto-correlation:
model$mcmc_acf(regex_pars = "beta")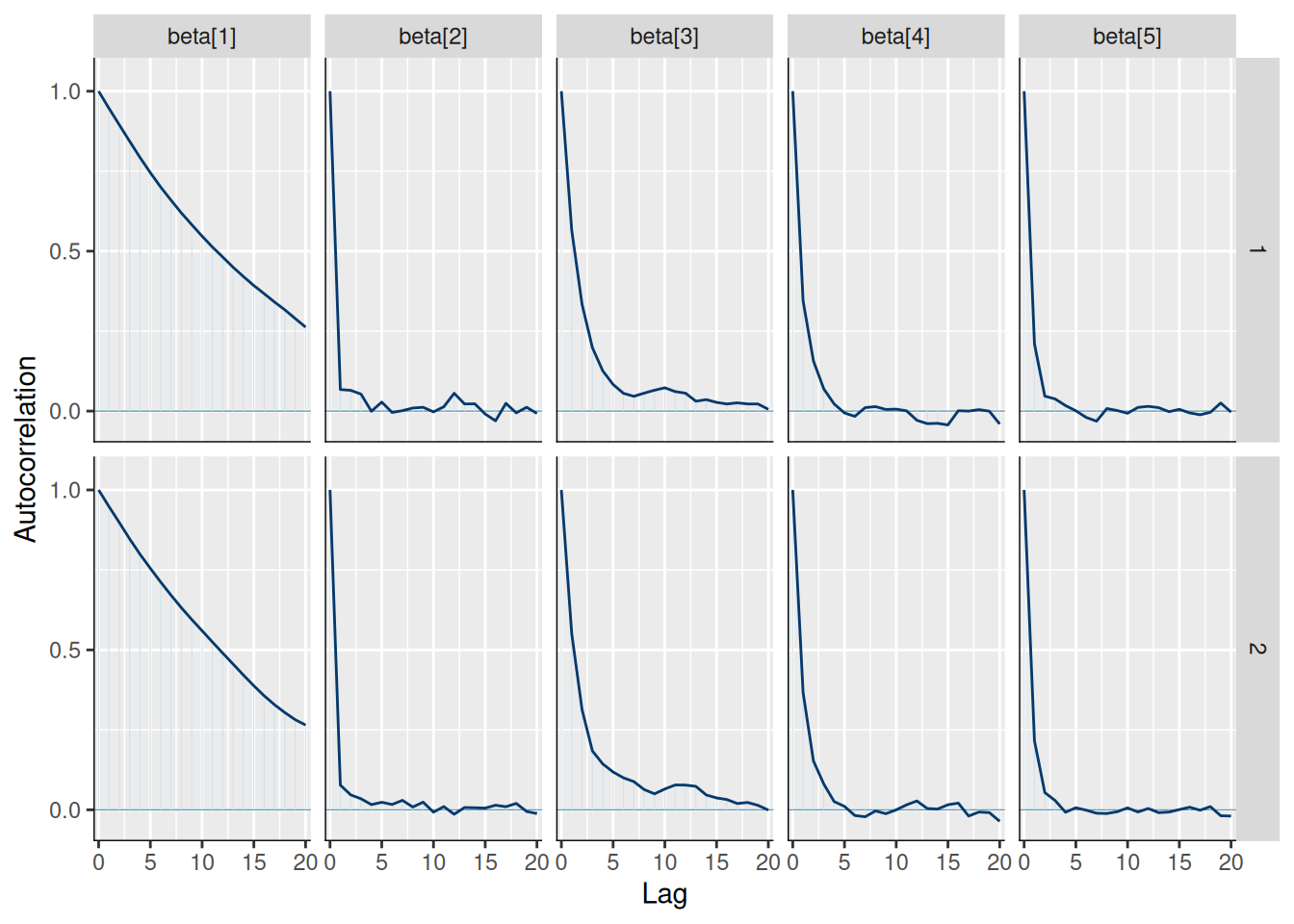
Effective sample size:
knitr::kable(model$n_eff())| x | |
|---|---|
| alpha | 209.3517 |
| beta[1] | 232.6273 |
| beta[2] | 4649.7930 |
| beta[3] | 2359.5125 |
| beta[4] | 3771.2112 |
| beta[5] | 5155.5969 |
| sigma | 7247.5324 |
| sigma_c | 1754.4095 |
| country_effect[1] | 691.3547 |
| country_effect[2] | 678.1495 |
| country_effect[3] | 752.5100 |
| country_effect[4] | 735.5818 |
| country_effect[5] | 755.6332 |
We can also plot the posterior distributions of each parameter:
model$plot_posteriors(pars = paste0("beta[", 1:length(covariates), "]")) +
ggplot2::scale_y_discrete(labels = covariates)
#> Scale for y is already present.
#> Adding another scale for y, which will replace the existing scale.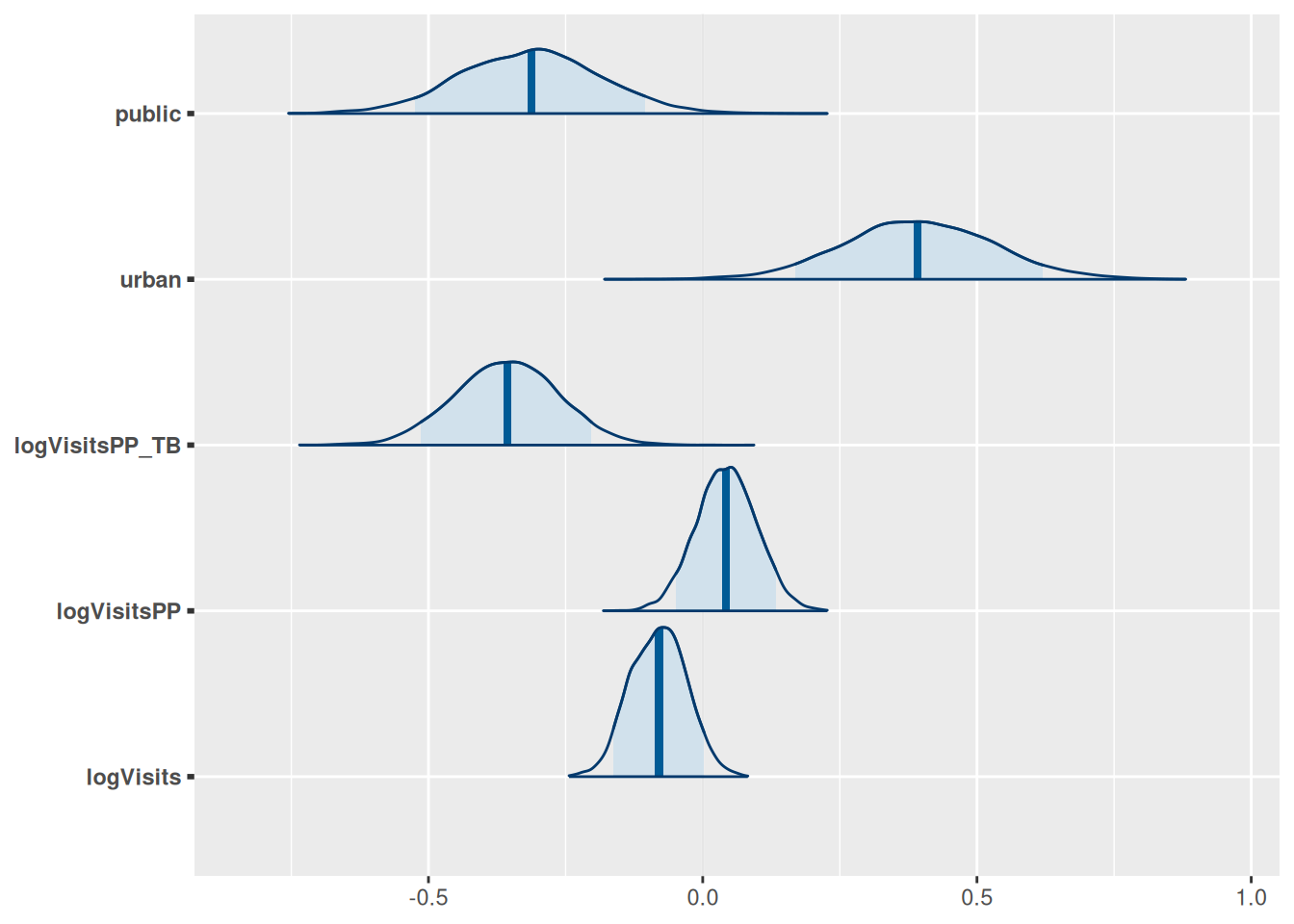
model$plot_posteriors(pars = paste0("country_effect[", 1:5, "]"))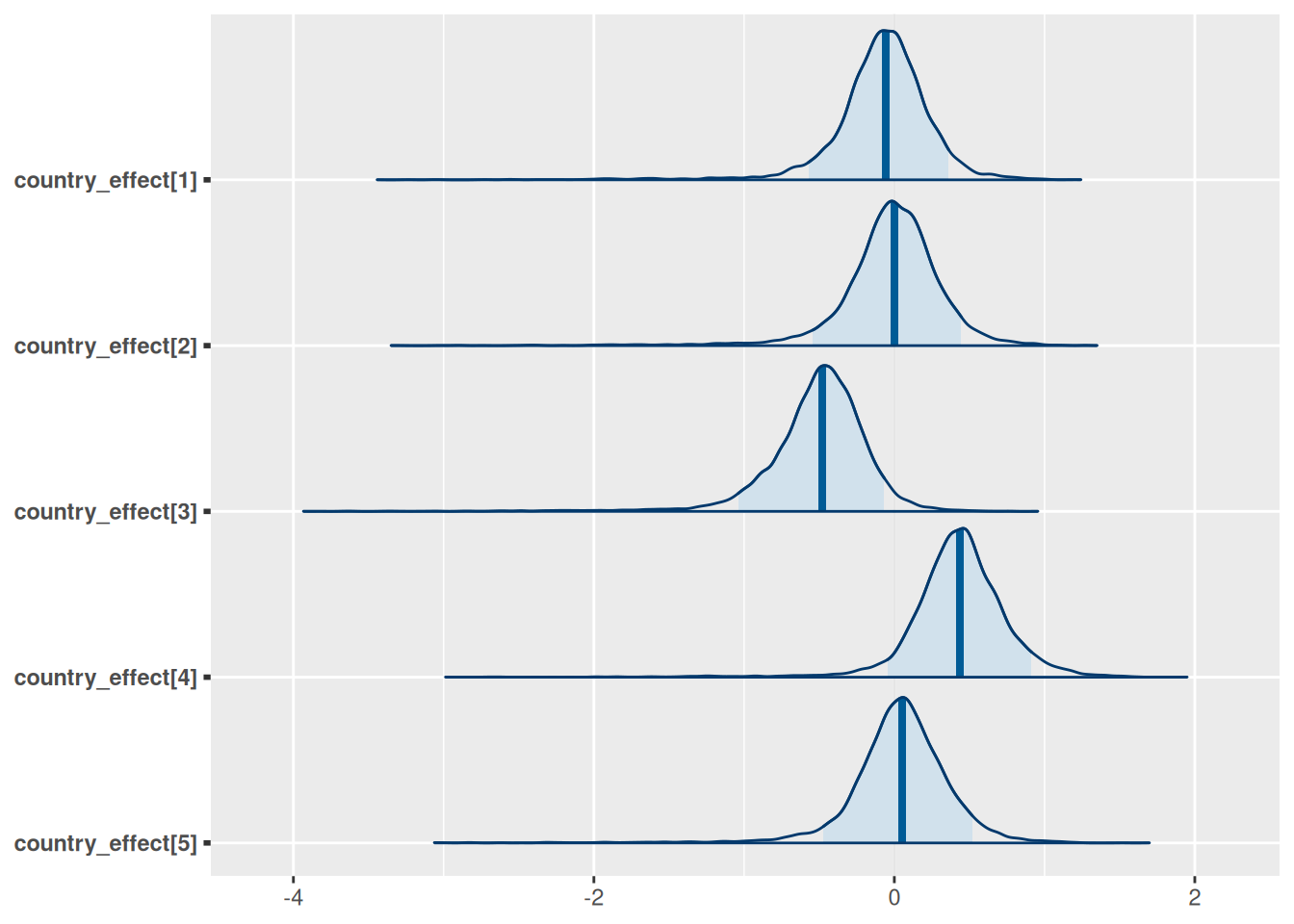
Generating predictions
We can now generate predictions for the training data and evaluate model fit:
# Generate predictions for the training data on log scale
dat <- model$training_data()
predictions <- model$predict(dat, scale = "log", summarised = TRUE)
head(predictions)
#> Summary of Posterior Distribution
#>
#> Observation | Mean | 95% CI
#> ---------------------------------
#> 1 | 3.47 | [2.25, 4.67]
#> 2 | 2.66 | [1.49, 3.84]
#> 3 | 2.10 | [0.94, 3.24]
#> 4 | 1.85 | [0.67, 3.01]
#> 5 | 2.25 | [1.09, 3.40]
#> 6 | 2.27 | [1.10, 3.42]
# Various measures of fit
performance <- model$performance(scale = "log")
knitr::kable(performance)| mae | rmse | ci_coverage | median_ci | bayesian_r2 |
|---|---|---|---|---|
| 0.4336165 | 0.5369405 | 0.9716981 | 2.322489 | 0.4964163 |
Visualising results
1. Predicted vs Observed
# Create scatter plot of predicted vs observed values
model$plot_fit(include_ci = FALSE, scale = "log")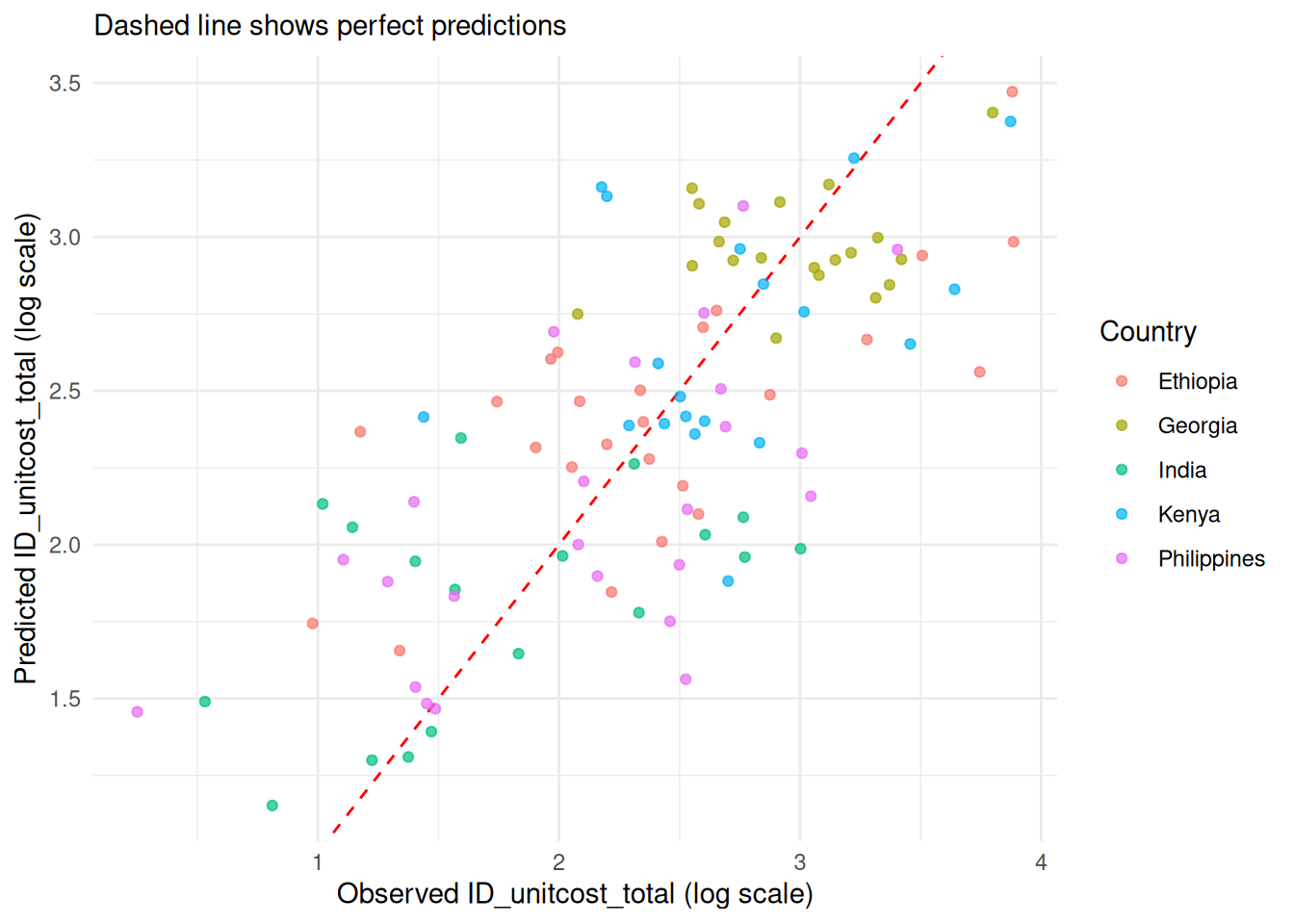
2. 95% Credible Prediction Intervals
# Plot with prediction intervals
model$plot_fit(include_ci = TRUE, scale = "log")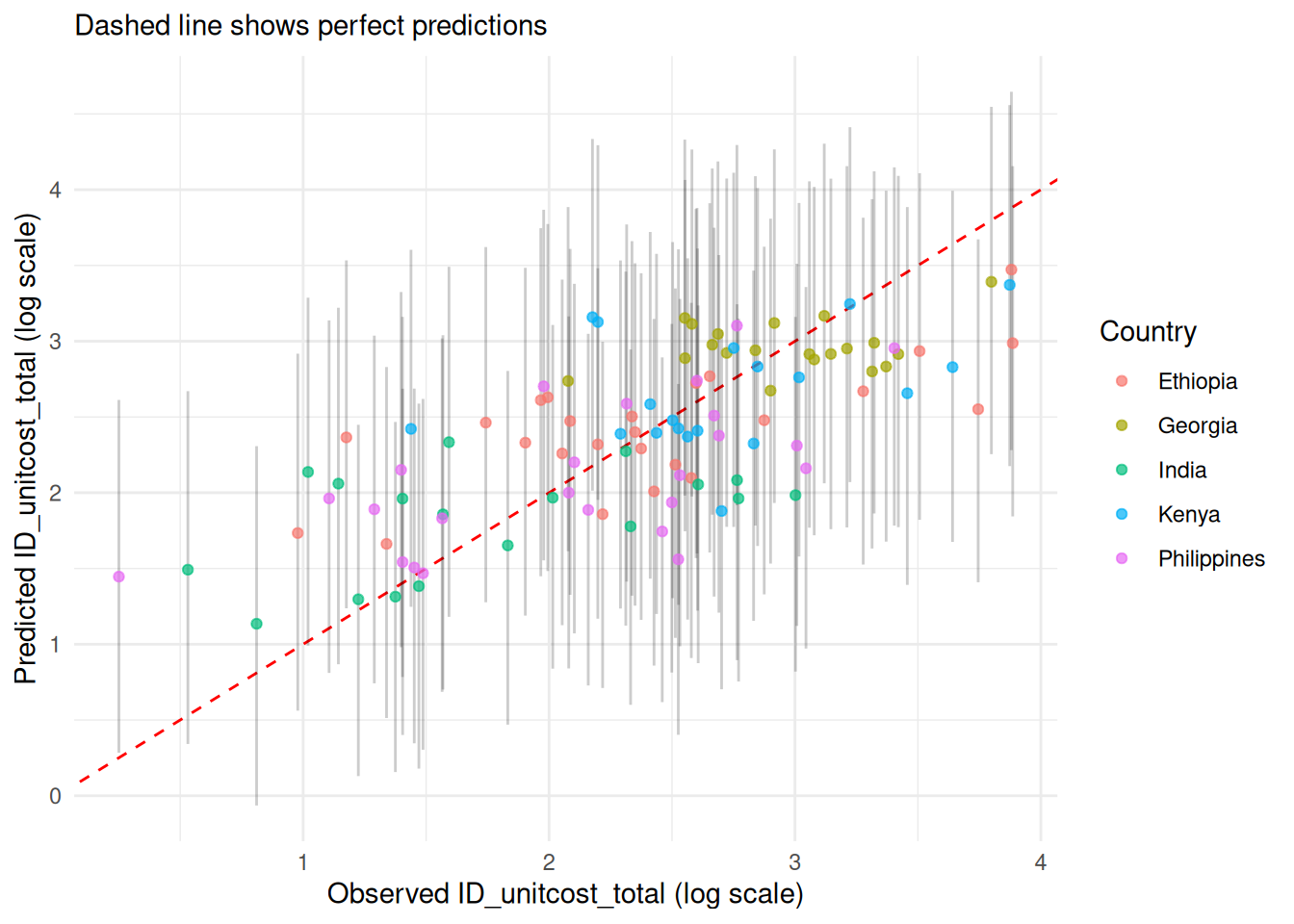
3. Residuals
model$plot_residuals(add_smooth = TRUE, color_by_country = TRUE)
#> Warning in private$.predict(dat, include_epsilon = FALSE, conditional = TRUE):
#> conditional = TRUE has no effect when there is only one output type
#> `geom_smooth()` using formula = 'y ~ x'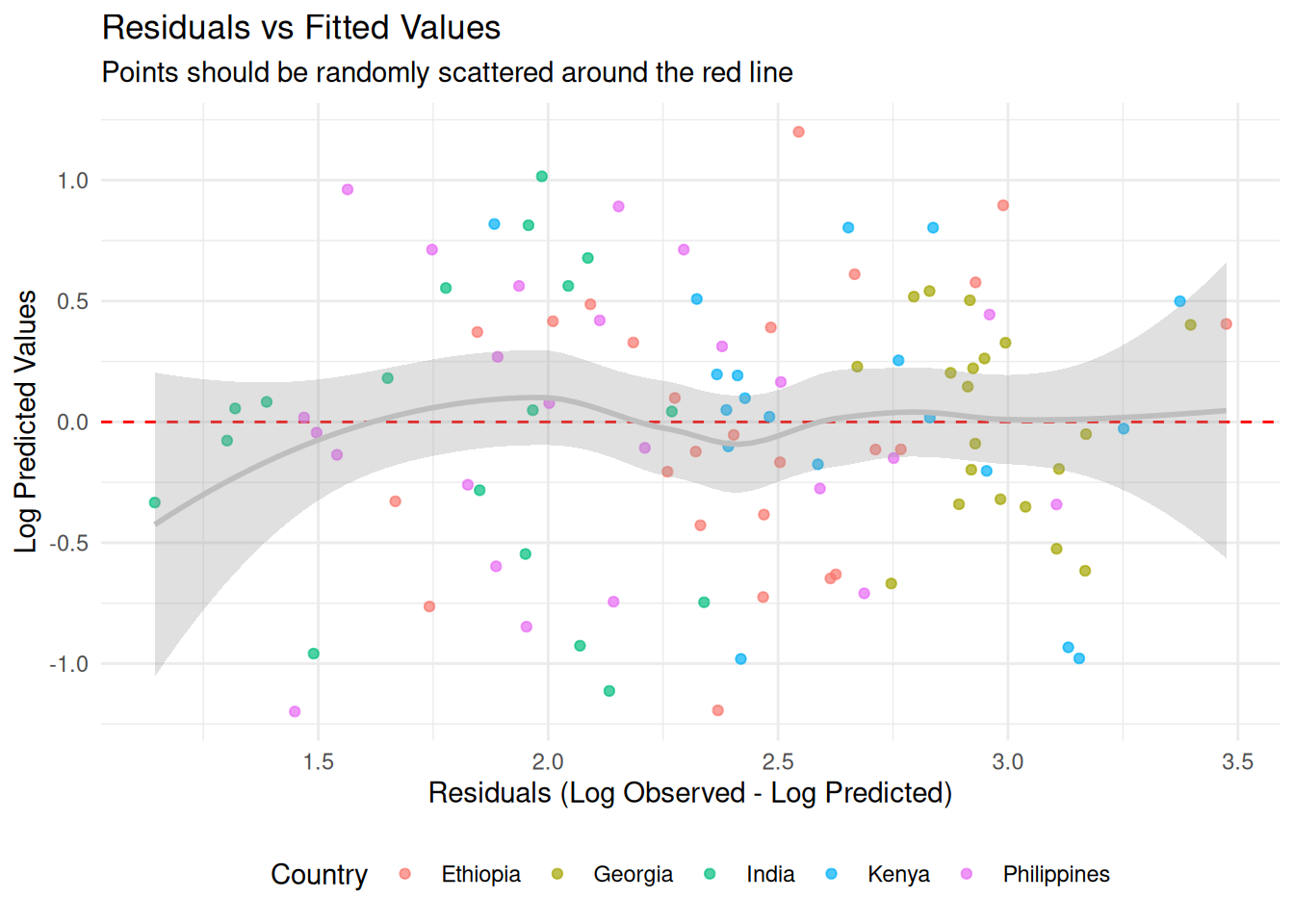
4. Country-Specific perfomance
# Performance by country
country_performance <- model$performance(by_country = TRUE)
colnames(country_performance) <- c("Country", "MAE",
"RMSE", "95% CI Coverage", "Median CI Width", "Bayesian R-squ")
knitr::kable(country_performance)| Country | MAE | RMSE | 95% CI Coverage | Median CI Width | Bayesian R-squ |
|---|---|---|---|---|---|
| Ethiopia | 6.944290 | 9.463919 | 0.9200000 | 34.37640 | 0.3903036 |
| Georgia | 6.849895 | 7.964144 | 1.0000000 | 52.34776 | 0.4400287 |
| India | 3.917845 | 4.984070 | 1.0000000 | 20.60835 | 0.3543627 |
| Kenya | 7.019623 | 9.436801 | 1.0000000 | 37.21178 | 0.4291543 |
| Philippines | 4.530958 | 5.523398 | 0.9583333 | 23.40307 | 0.4806371 |
model$plot_fit() +
ggplot2::facet_wrap(~country, scales = "free")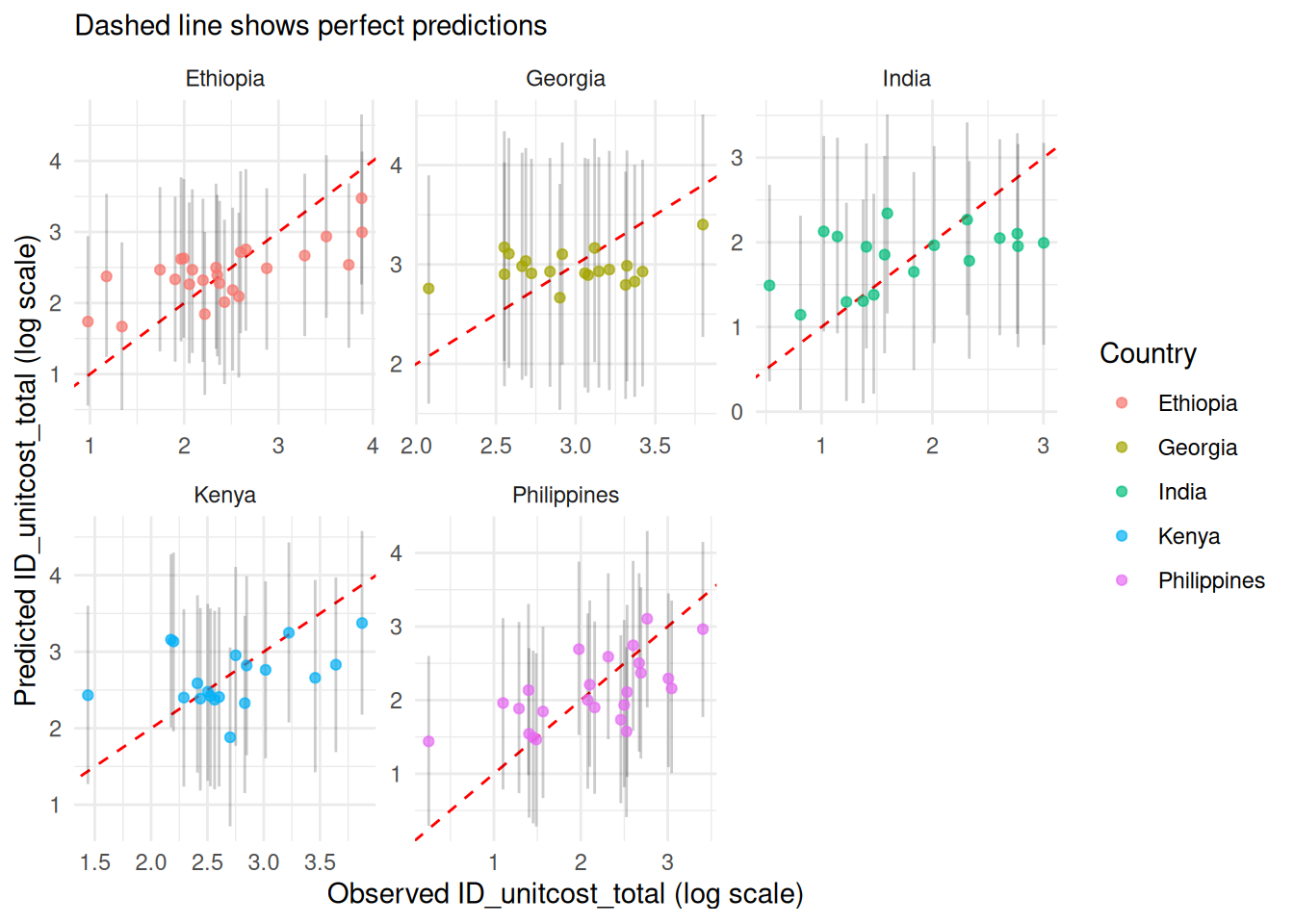
5. Out-of-sample performance
We can check for overfitting and estimate out-of-sample performance using k-fold cross-validation. Here we use 3 folds for quick compilation; in practice, 10 or 20 folds would give a more accurate picture.
res <- model$k_fold_cv(k_folds = 3,
n.iter = 10000,
n.burnin = 1000,
n.adapt = 1000,
scale = "log")
#> Processing fold 1 of 3
#> Single output type detected. Not including output-level random effects in model.
#> Calling 3 simulations using the parallel method...
#> Following the progress of chain 1 (the program will wait for all chains
#> to finish before continuing):
#> Welcome to JAGS 4.3.2 on Wed Jun 17 11:31:06 2026
#> JAGS is free software and comes with ABSOLUTELY NO WARRANTY
#> Loading module: basemod: ok
#> Loading module: bugs: ok
#> . . Reading data file data.txt
#> . Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 70
#> Unobserved stochastic nodes: 83
#> Total graph size: 879
#> . Reading parameter file inits1.txt
#> . Initializing model
#> . Adapting 1000
#> -------------------------------------------------| 1000
#> ++++++++++++++++++++++++++++++++++++++++++++++++++ 100%
#> Adaptation successful
#> . Updating 1000
#> -------------------------------------------------| 1000
#> ************************************************** 100%
#> . . . . . . Updating 10000
#> -------------------------------------------------| 10000
#> ************************************************** 100%
#> . . . . Updating 0
#> . Deleting model
#> .
#> All chains have finished
#> Simulation complete. Reading coda files...
#> Coda files loaded successfully
#> Finished running the simulation
#> Compiling rjags model and adapting for 1000 iterations...
#> Obtaining DIC samples from 100 iterations...
#> Warning in doTryCatch(return(expr), name, parentenv, handler): Model may not
#> have converged. Max rhat is 1.24894995712364
#> Model fitted successfully with 3 chains and 10000 iterations.
#> Processing fold 2 of 3
#> Single output type detected. Not including output-level random effects in model.
#> Calling 3 simulations using the parallel method...
#> Following the progress of chain 1 (the program will wait for all chains
#> to finish before continuing):
#> Welcome to JAGS 4.3.2 on Wed Jun 17 11:31:07 2026
#> JAGS is free software and comes with ABSOLUTELY NO WARRANTY
#> Loading module: basemod: ok
#> Loading module: bugs: ok
#> . . Reading data file data.txt
#> . Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 71
#> Unobserved stochastic nodes: 84
#> Total graph size: 891
#> . Reading parameter file inits1.txt
#> . Initializing model
#> . Adapting 1000
#> -------------------------------------------------| 1000
#> ++++++++++++++++++++++++++++++++++++++++++++++++++ 100%
#> Adaptation successful
#> . Updating 1000
#> -------------------------------------------------| 1000
#> ************************************************** 100%
#> . . . . . . Updating 10000
#> -------------------------------------------------| 10000
#> ************************************************** 100%
#> . . . . Updating 0
#> . Deleting model
#> .
#> All chains have finished
#> Simulation complete. Reading coda files...
#> Coda files loaded successfully
#> Finished running the simulation
#> Compiling rjags model and adapting for 1000 iterations...
#> Obtaining DIC samples from 100 iterations...
#> Model fitted successfully with 3 chains and 10000 iterations.
#> Processing fold 3 of 3
#> Single output type detected. Not including output-level random effects in model.
#> Calling 3 simulations using the parallel method...
#> Following the progress of chain 1 (the program will wait for all chains
#> to finish before continuing):
#> Welcome to JAGS 4.3.2 on Wed Jun 17 11:31:08 2026
#> JAGS is free software and comes with ABSOLUTELY NO WARRANTY
#> Loading module: basemod: ok
#> Loading module: bugs: ok
#> . . Reading data file data.txt
#> . Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 71
#> Unobserved stochastic nodes: 84
#> Total graph size: 891
#> . Reading parameter file inits1.txt
#> . Initializing model
#> . Adapting 1000
#> -------------------------------------------------| 1000
#> ++++++++++++++++++++++++++++++++++++++++++++++++++ 100%
#> Adaptation successful
#> . Updating 1000
#> -------------------------------------------------| 1000
#> ************************************************** 100%
#> . . . . . . Updating 10000
#> -------------------------------------------------| 10000
#> ************************************************** 100%
#> . . . . Updating 0
#> . Deleting model
#> .
#> All chains have finished
#> Simulation complete. Reading coda files...
#> Coda files loaded successfully
#> Finished running the simulation
#> Compiling rjags model and adapting for 1000 iterations...
#> Obtaining DIC samples from 100 iterations...
#> Warning in doTryCatch(return(expr), name, parentenv, handler): Model may not
#> have converged. Max rhat is 1.14508347405207
#> Model fitted successfully with 3 chains and 10000 iterations.
fit <- res |>
group_by(fold) |>
summarise(rmse = sqrt(mean((observed-mean)^2)),
mae = mean(abs(observed-mean)))
knitr::kable(fit)| fold | rmse | mae |
|---|---|---|
| 1 | 0.6162097 | 0.5028093 |
| 2 | 0.6396298 | 0.5131749 |
| 3 | 0.5121990 | 0.4176273 |
Reproducing the fitted models installed with the package
There are three pre-fitted models installed with the package:
-
unitcost(): predicts the cost of a single outpatient visit -
unitcost_fixed(): predicts the fixed costs associated with a single outpatient visit -
unitcost_ohd(): predicts the fixed costs associated with a single outpatient visit
# economic cost models
mod_unit <- unitcost()
mod_unit$fit(seed = 1)
samples <- mod_unit$samples()
DIC <- mod_unit$mcmc_DIC(summarised = FALSE)
saveRDS(samples, "inst/econ/posterior_samples.rds")
saveRDS(DIC, "inst/econ/posterior_samples_dic.rds")
mod_unit_fixed <- unitcost_fixed()
mod_unit_fixed$fit(seed = 1)
samples_fixed <- mod_unit_fixed$samples()
DIC_fixed <- mod_unit_fixed$mcmc_DIC(summarised = FALSE)
saveRDS(samples_fixed, "inst/econ/posterior_samples_fixed.rds")
saveRDS(DIC_fixed, "inst/econ/posterior_samples_dic_fixed.rds")
mod_unit_ohd <- unitcost_ohd()
mod_unit_ohd$fit(seed = 1)
samples_ohd <- mod_unit_ohd$samples()
DIC_ohd <- mod_unit_ohd$mcmc_DIC(summarised = FALSE)
saveRDS(samples_ohd, "inst/econ/posterior_samples_ohd.rds")
saveRDS(DIC_ohd, "inst/econ/posterior_samples_dic_ohd.rds")Executing the above code will reproduce exactly the posterior samples installed with this package. The functions unitcost(), unitcost_fixed() and unitcost_ohd() use the saved posteriors to load the models without requiring fitting at runtime.